
Last week, I found myself needing to filter things alphabetically, using regex. Basically, this is because PHPUnit lets you filter what tests you run with regex, and we (we being Etsy) have enough tests that we have to split them into many parts to get them to run in a reasonable amount of time.
We've already got some logical splits, like separating unit tests from db-related integration tests and all that jazz. But at some point, you just need to split a test suite into, say, 6 pieces. When the option you have to do this is regex, well, then you just have to split it out by name.
Splitting Tests by Name? That's not Smart.
No, no it's not. But until we have a better solution (which I'll talk about in a later post), this is what we're stuck with. Originally, we just split the alphabet into the number of pieces we required and ran the tests that way. Of course, this doesn't result in even remotely similar runtimes on your test suites.
Anyway, since we're splitting things up by runtime but we're stuck with using regex, we might as well use alphabetic sorting. That'll result in relatively short regular expressions compared to just creating a list of tests.
To figure out where in the alphabet to make the splits for our tests, I downloaded all of our test results for a specific test suite and ran it through a parser that could handle JUnit-style output (XML files with the test results). I converted them into CSV's, and then loaded them into a Google Spreadsheet:

This made it trivial to figure out where to split the tests alphabetically to even out the runtimes. The problem was, the places where it made sense to split our tests weren't the easiest places to create an alphabetic split. While it would've been nice if the ranges had been, say, A-Cd or Ce-Fa, instead they decided to be things like A-Api_User_Account_Test or Shop_Listings_O-Transaction_User_B.
It's not easy to turn that into regex, but there is at least a pattern to it. I originally tried creating the regex myself – but quickly got in over my head. After about 100 characters in my regex, my brain was fried.
I decided that it'd be easier, quicker, and less error-prone to write a script that could handle it for me.
Identifying the Pattern
It's really quite simple once you break it down. To find if a String is between A and Bob (not including Bob itself), you need a String that meets the following conditions:
- Starts with
Aora, OR - Starts with
Borb, AND:- The second character is
A-Mora-mOR - The second character is
Ooro, AND:- The third character is
Aora
- The third character is
- The second character is
In a normal 'ole regular expression, this looks like the following (ignoring all special characters):
^[Aa].*|^([Bb](.|[Oo]([Aa]|$)|$)).*$Now, if we've got something that complicated just to find something up to Bob, you can likely figure out that the rule would get much longer if you have many characters, like Beta_Uploader_Test_Runner.
There's a recognizable pattern, but once again, it's pretty complex and hard for my weak human brain to grok when it gets long. Luckily, this is what computers are very, very good at.
Formulating the Regex
To get a range between two alphabetic options, you generally need 3 different regex rules. Let's say we're looking for the range Super-Whale. First, you need the range from the starting point to the last alphabetic option that still starts with the same letter. So, essentially, you need Super-Sz. The second thing you need is anything that starts with a letter between the first letter of the starting point and the first letter of the end point. So our middle range would be T-V. The last part needs to be W-Whale.
By way of an example, here's a more simple version of the first part – in this case, it's Hey-Hz, color-coded so that you can see what letter applies to which part of the regular expression:

Next up, we're using the same word as if it were the second part. In this case, H-Hey:

Since the middle part is super simple, I won't bother detailing that. With those three elements, we've got our regex range. Of course, there are some more details around edge cases and whatnot, but we'll ignore those for now. It's much simpler for the purposes of blog posts.
Doing some Test-Driven Development
I decided that the best way to make this, you know, actually work, was to write a bunch of tests that would cover many of the edge cases that I could hit. I needed to make sure that these would work, and writing a bunch of tests is a good way to do so.
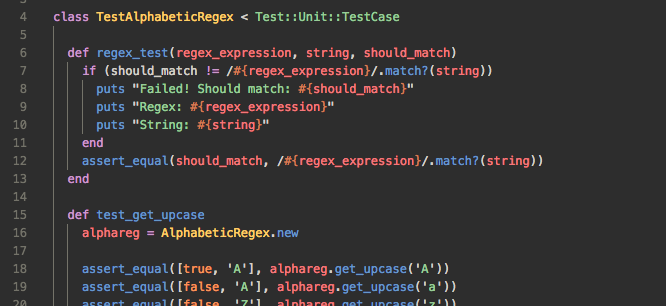
This helped me know exactly what was going wrong, and I wrote more tests as I kept writing the code. For every method that I wrote, I wrote tests to go along with it. If I realized that I had missed any necessary tests, I added them in, too.
Overall, I'd say this significantly increased my development speed, and it definitely helped me be more confident in my code. Tests are good. Don't let anyone tell you otherwise.
The Code on GitHub
Of course, it doesn't make sense to restrict this code to just me. I couldn't find any good libraries to handle this for me, so I wrote it myself. But really, it only makes sense to make this available to a wider audience.
I've still got some issues to work out, and I need to make a Ruby gem out of it, but in the meantime, feel free to play around with the code: https://github.com/russtaylor/alphabetic-regex
I'm really hoping that someone else will find this code to be useful. If anyone has any questions, comments, or suggestions, feel free to let me know!
Leave a Reply