At work recently, we had a need to generate diffs between two different directory trees. This is so that we can handle deploys, but it’s after we’ve already generated assets, so we can’t just use git for the diff creation, since git diff doesn’t handle files that aren’t tracked by git itself. We looked into using GNU’s diffutils, but it doesn’t handle binary files.
We tried investigating other methods for deploying our code, but thought it would still be simplest if there was some way to generate just a ‘patch’ of what had changed.
Luckily, one of the Staff Engineers at Etsy happened to know that rsync had just such an option hiding in its very long man page. Because rsync handles transferring files from one place to another, whether it’s local or remote, it has to figure out the diffs between files anyway. It’s really nice that they’ve exposed it so that you can use the diffs themselves. The option that does this is called ‘Batch Mode’, because you can use it to ‘apply’ a diff on many machines after you’ve distributed the diff file.
Creating the Diff
To create the diff itself, you’ll need to first have two directories containing your folder structure – one with the ‘previous’ version and one with the ‘current’ version. In our case, after we run each deploy, we create a copy of the current directory so that we can use that as our previous version to build our next diff.
Running that command will give you two files, diff and diff.sh. You can just use the .sh file to apply your diff, but you don’t have to. As long as you remember to use the same flags when applying your diff, you’ll be fine. You can also use any filename that you want after the =.
Also, it’s important to note that running this command will update/deploy/previous to the contents of /deploy/current. If you want to keep /deploy/previous as-is so that you can update it later, use --only-write-batch instead of just --write-batch.
Applying the Diff
Next up, you’ll want to distribute your diff to whatever hosts are going to receive it. In our case, we’re uploading it to Google Cloud Storage, where all the hosts can just grab it as necessary.
On each host that’s applying the diff, you’ll want to just run something like the following:
rsync --read-diff=/path/to/diff /deploy/directory
Remember, you need to use the same flags when applying your diff as you did when you created your diff.
In our testing, this worked well for applying a diff to many hosts – updating around 400 hosts in just about 1 minute (including downloading the ~30MB diff file to each host).
Caveats
This will fail if the diff doesn’t apply cleanly. So, essentially, if one of your hosts is a deploy behind, you should make absolutely sure that you know that, and don’t try to update it to the latest version. If you try to anyway, you’ll probably end up with errors in the best case, or a corrupt copy of your code in the worst case. We’re still working on making our scripts handle the potential error cases so that we don’t end up in a corrupt state.
I hope this is helpful to you! If you’ve got any thoughts, questions, or corrections, drop them in the comments below. I’d love to hear them!
In Ruby on Rails, it’s easy to build custom functions to calculate something and then display the result in your views. While this simplicity is nice, it doesn’t come without its drawbacks.
Recently, when working on a simple app, I came across a situation where loading a page was taking 0.5 seconds. This may not sound like a lot (and wouldn’t be for most sites), but in an app as simple as mine, it’s a sign that something is taking way longer than it should. Luckily, it wasn’t too difficult to determine what it was.
The Problem
Let’s start with an example: say you’re building an application that will contain purchases from a grocery store. You probably want to link the items sold in a purchase with the record from that purchase, right? Well, somewhere you’re going to have to calculate the total. Of course, I’m assuming that you don’t want the customer to calculate the total.
You could calculate the total every time that you need to load the record of the purchase, but first let’s walk through what would be happening when you calculated the total. If there are, say, 30 items in that purchase, you’ll need to load every single one of those items so that you can grab the price (we’re assuming prices don’t change for this example) and add them all together.
As you might imagine, this isn’t a very efficient way to go about things. We’d rather offload some of that computation (that would be happening an awful lot) to the disk, instead. After all, it’s generally easier to store a few bytes than spend valuable CPU time recalculating it every time you need it.
In my case, that’s exactly the sort of thing that was happening. I was working to calculate a field that wouldn’t change often but that involved loading lots of links to other records. On top of that, it was going to be loaded pretty often. It’s much more efficient for me to just store that value than to calculate it for every request.
The Solution
You’ll need to add a new field to your database, which means you’ll need to add a database migration, something like this:
After you run your migration (rails db migrate), you’ll have your new field. Now, if you generated all your scaffolding, that’d be showing up in your user interface. That’s not what you want to do, though, since we’re trying to make this easier for your users and calculate it on their behalf.
Thus, we’re going to add something like the following to our model:
before_save :calculate_receipt_total
def calculate_receipt_total
sum_value = x + y # Whatever you need to do here to calculate
self.total = sum_value
end
Now that method will run automatically before the record is saved, and place our calculated value into the total value, which means it’ll end up there in the database, as well.
Like I said, just how much benefit (if any) you’ll get out of this depends on your exact circumstances, but in my case it reduced a 500 ms page load to around 100 ms, which is clearly a substantial improvement.
If you’ve got any questions, drop them in the comments, and I’ll do my best to answer them!
I know I’m really late to the party, but I’m just finally creating something from scratch in Ruby on Rails. I’ve dealt a tiny bit with Rails before, but it was mostly just in helping my brother with CSS stuff, which obviously isn’t working on the Rails backend.
Anyway, now that I’ve started working with Rails (to build a simple app for my wife), I’ve found myself needing to learn how to do things in Rails 5. The problem is, a lot of things have changed in Rails, but most Google search results for ‘Rails …’ or ‘Ruby on Rails …’ end up with articles that are at least several years old. It’s hard to figure out what actually applies to Rails 5, vs. any other version of Rails. Thus, I’ve decided to write up some of my findings so that they’re hopefully helpful for someone else.
I’ll assume that you already know how to create your initial models, views, and controllers. If you don’t, check out this guide to get started.
Creating Many:Many Associations
Creating links between your records is pretty straightforward. I’m going to be using hypothetical ‘products’ and ‘purchases’ tables, which aren’t necessarily a perfect use-case for this, but they’re good enough. We can use Rails’s simple generator to make a link between our tables:
All that’s going to do is generate a migration file (if you want those indexes, uncomment the two t.index lines):
class CreateJoinTableProductsPurchases < ActiveRecord::Migration[5.2]
def change
create_join_table :products, :purchases do |t|
# t.index [:product_id, :purchase_id]
# t.index [:purchase_id, :product_id]
end
end
end
After updating our database with the migration (rails db:migrate), we just need to add a has_and_belongs_to_many to each of our models:
class Product < ApplicationRecord
has_and_belongs_to_many :purchases
end
class Purchase < ApplicationRecord
has_and_belongs_to_many :product
end
I know that using has_and_belongs_to_many may be going out of favor, but I haven’t had time to look at the alternative just yet, so I’m sticking with HABTM for now.
Creating Many:Many Links in the UI
Now you’ve got a link between your two models, but no convenient way to create any links! That’s what we’ll be focusing on next. Luckily, it’s pretty easy, you just need to know what to do.
Showing Many:Many Forms
First off, in the form for the ‘products’ side of our relationship, we’ll simply add the following:
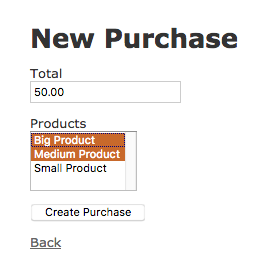
If you’re using Rails’s scaffold generator, you’ll add it to app/views/<model_name>/_form.html.erb. This creates a list of all the ‘products’ (in the example code) in the form for a purchase, and allows you to select multiple products.
If you’d like, you can add similar code to the other side of your relationship. In my case, I’m just adding it on one side. The form will end up looking something like this:
You can use ‘Ctrl/Cmd+click’ to select more than one item in the list, but that’s really all there is to it. It’s a very basic form, but it’ll do the trick.
Of course, you can do something more advanced, but we’re just covering the basics here. Ideally, I’d like a multi-select autocompleting textbox. Hopefully some day in the near future I’ll be able to put a guide up here on how to do that.
Saving Many:Many Relationships
Now, to make our selections actually save, we’ve got to add something to the controller. Since I’m only allowing the creation of links from the ‘Purchase’ UI, I put this code in my app/controllers/purchases_controller.rb file, in both the create and the update methods:
params[:purchase][:product_ids].each do |product_id|
unless product_id.empty?
product = Product.find(product_id)
@boarding.products << product
end
end
And that’s all there is to it! When you either create or update a ‘purchase’, your selection for its ‘products’ will be saved.
Viewing Many:Many Links in the UI
So now that we’re able to easily create links, it would be nice if we could view those links. So let’s make it possible to see the list of ‘products’ in a ‘purchase’. Using the Rails scaffolding, we’re going to want to expose these in both the ‘list’ view and the ‘single’ view for each side of our link. You can pick if the same applies to you.
In our app/views/purchases/index.html.erb, we’re going to add the following to a new <td> that will display the ‘products’ in each ‘purchase’. Don’t forget to add an associated <th> in the header, as well.
<%= purchase.products.map(&:name).join(', ') %>
Then, upon loading /purchases, you’ll see something a lot like this:
Next up, we need to add some very similar code to our app/views/purchases/show.html.erb file (but note the @ in the name of the purchase variable:
<%= @purchase.products.map(&:name).join(', ') %>
And then you’ll have something like this when you view your ‘purchase’ (at a URL like /purchases/2):
Conclusion
That’s it! As I said, this isn’t a perfect use-case for a many:many relationship, but it’s at least an overview of how to create the UI elements that will allow you to save and view such relationships.
If you want to take a look at the code in its entirety, it’s available on GitHub. And, if you’ve got any tips or comments, drop them in the ‘comments’ section below! That’s what it’s there for!
This is going to be a quick post – but I wanted to put it here for my own reference, since it’s something I have to look up pretty often. I might as well make my notes about it public so that others can benefit, too.
What are ‘Contexts’?
In Kubernetes, a Context is essentially the configuration that you use to access a particular cluster & namespace with a user account. In most cases, this will be your user account, but it could also be a service account.
In my particular case, there are at least a few Kubernetes clusters that I need to access pretty regularly. We have one in our data center and two or three different clusters (depending on the day) configured in GCP to work on our migration there. When I need to work in one cluster, I need to remember how to activate the context that grants me access to that cluster.
This will show all your configured contexts in Kubernetes. I included the | tr ... to replace the spaces with newlines so that it’s easier to parse the results. This way, you can easily see the exact names of your contexts, so that you can easily switch between them.
Show your Current Context
kubectl config current-context
This just shows your current context. It’s pretty self-explanatory, but I often forget the exact syntax that lists my context.
Set your Context
kubectl config use-context <context_name>
And this, not surprisingly, sets your context. So if you need to switch from your minikube context to your gcp-project-cluster-context, you just use this nifty command, and suddenly your commands are pointing at an entirely different cluster.
As of last month (March 8th-ish, 2018), Let’s Encryptsupports wildcard certificates! This is great news, because it means that those of us who like using tons of subdomains can now get one cert for all our subdomains, rather than having to get a cert for every single subdomain.
As you may know, Certbot is the tool provided by the EFF that you use to interact with and issue certs from Let’s Encrypt. It used to be called letsencrypt-auto, but when the EFF took it over, it switched names to Certbot.
Now, it’s not quite as easy to get wildcard certs as it is to get normal certs – mainly because there are some prerequisites. The nice thing is, some of these prerequisites make it easier to issue and renew certificates without temporarily disabling your web server.
Prerequisites
The certbot docs aren’t super clear about a lot of this, so you have to do some digging, but essentially it boils down to this:
Wildcard certificates are only available if you use the ‘DNS’ method of verification.
DNS verification requires that you use a DNS provider with a supported API. This is because you need to be able to quickly create TXT records so that Let’s Encrypt can verify them. You can do this manually, but it seems like a pain. The supported DNS providers for automatic updates are:
I’ve decided to just go with Google Cloud DNS, because I’m already doing some other stuff in Google Cloud Platform, and it’s really quite affordable for what I need. Sure, it’s not as cheap as just using the DNS that your registrar provides, but I know mine doesn’t provide an API, especially not one supported by certbot.
Setting up Google Cloud DNS
To get Google Cloud DNS set up, you’ll obviously need a Google account. If you don’t have one, well, I’ll leave it to you to get one. Then you’ll need to set up Google Cloud Platform – once again, I’ll leave that to you. You’ll also need to set up a project for your DNS records. If you already have a project, you can feel free to use that.
Set up a Service Account
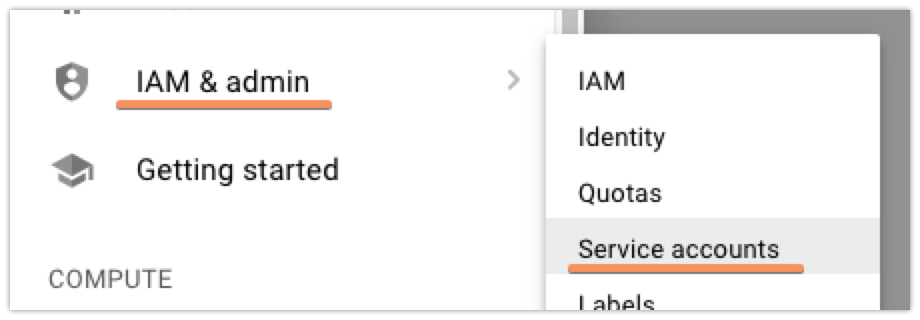
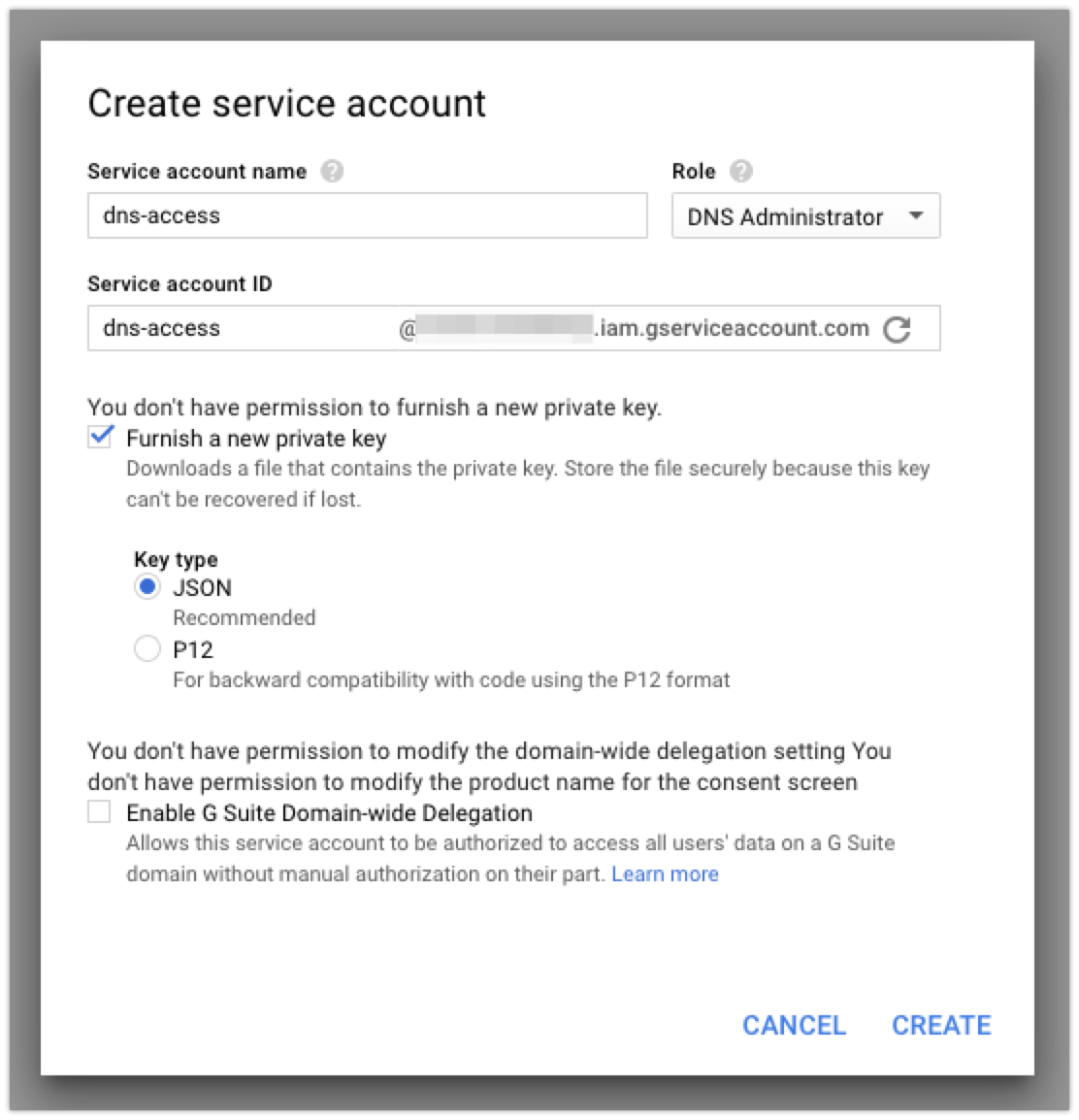
Next up, you’ll need to set up a ‘Service Account’ that will let you access the GCP DNS API with restricted permissions, so that you can safely put the credentials on a box that’ll handle your renewals without having to fully authenticate with GCP yourself. To start out, click the ‘hamburger’ menu on the left, then find ‘IAM & admin’, and finally ‘Service Accounts’:
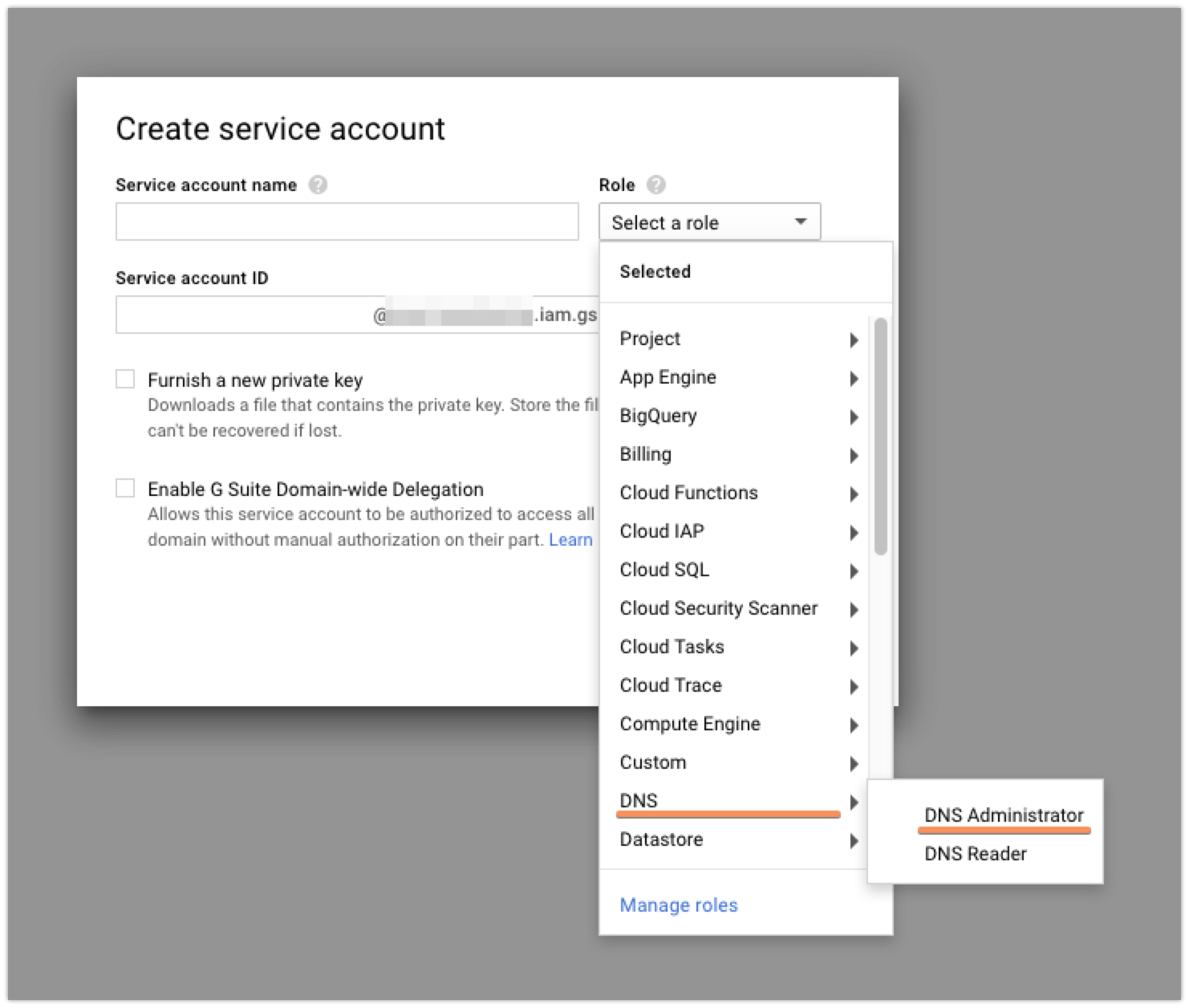
Once there, you’re going to want to click the ‘Create Service Account’ button at the top. Currently, the Cloud DNS permissions and whatnot are in beta, so that means that while you could create a custom role that would have exactly the permissions that you need, those are subject to change and there’s a decent chance that you’d need to recreate your service account later. To avoid this, I just made my new service account into a ‘DNS Administrator’. It’s got more permissions than I strictly need, but I’m not super worried about that.
After you give your service account a name, you’ll want to check the ‘Furnish a new private key’ box so that you can download the credentials file that you’ll need to access the API later:
When you create your account, it should automatically download the JSON file with the credentials. I copied that key to the server I’m using to issue certificates (my good ‘ole Linode server!) so that I can use it later.
Creating your DNS Zone
Naturally, to do anything with DNS, you need to have a domain to do something with. You’ll have to point your registrar to Google/your DNS provider of choice before you can actually issue a wildcard certificate.
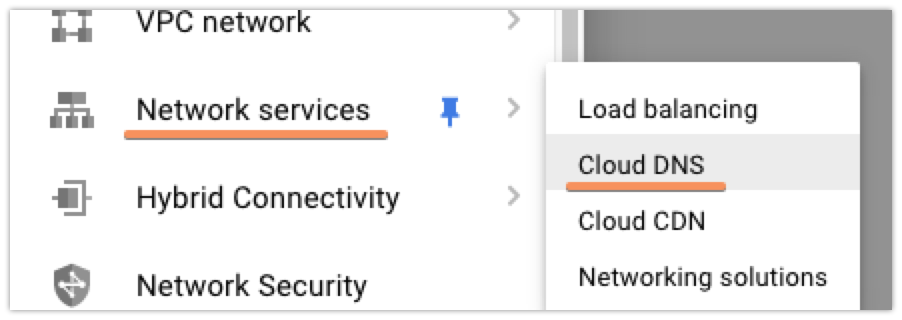
I set up my domain in Google Cloud DNS before I switched anything at my domain registrar, so that I wouldn’t have to worry about any downtime where my site was unreachable. To do this, you’ll first want to access the Cloud DNS control panel in GCP:
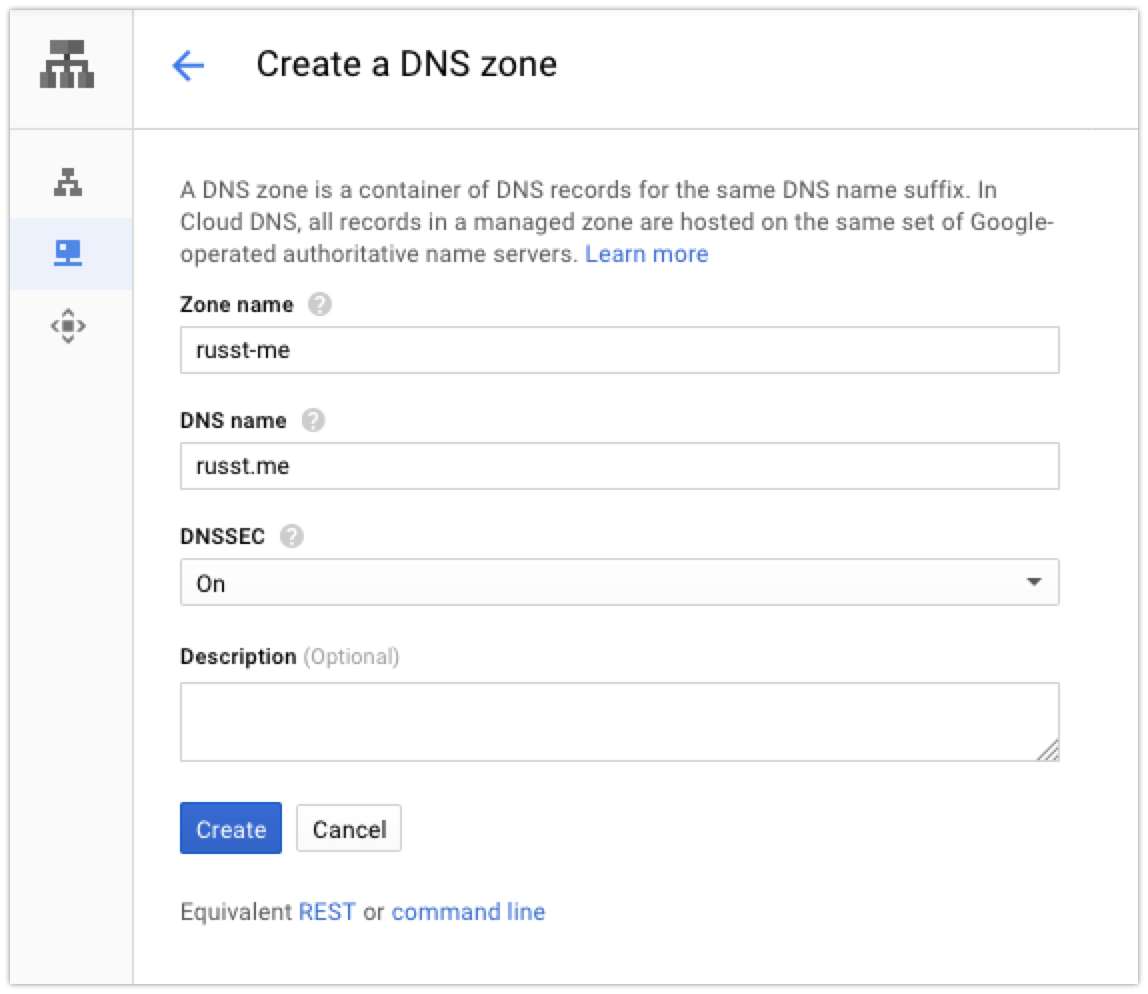
Next up, click the ‘Create Zone’ button at the top of the console. Then, you’ll enter the information for your domain:
Then you’ll create some records for your domain. At the very least, you’ll probably want one A record pointing to your server, but you can also create subdomains or whatever else you want. If you’re copying your config from somewhere else, put in all the records that you had on your previous provider. I had quite a few records, but even so it didn’t take very long.
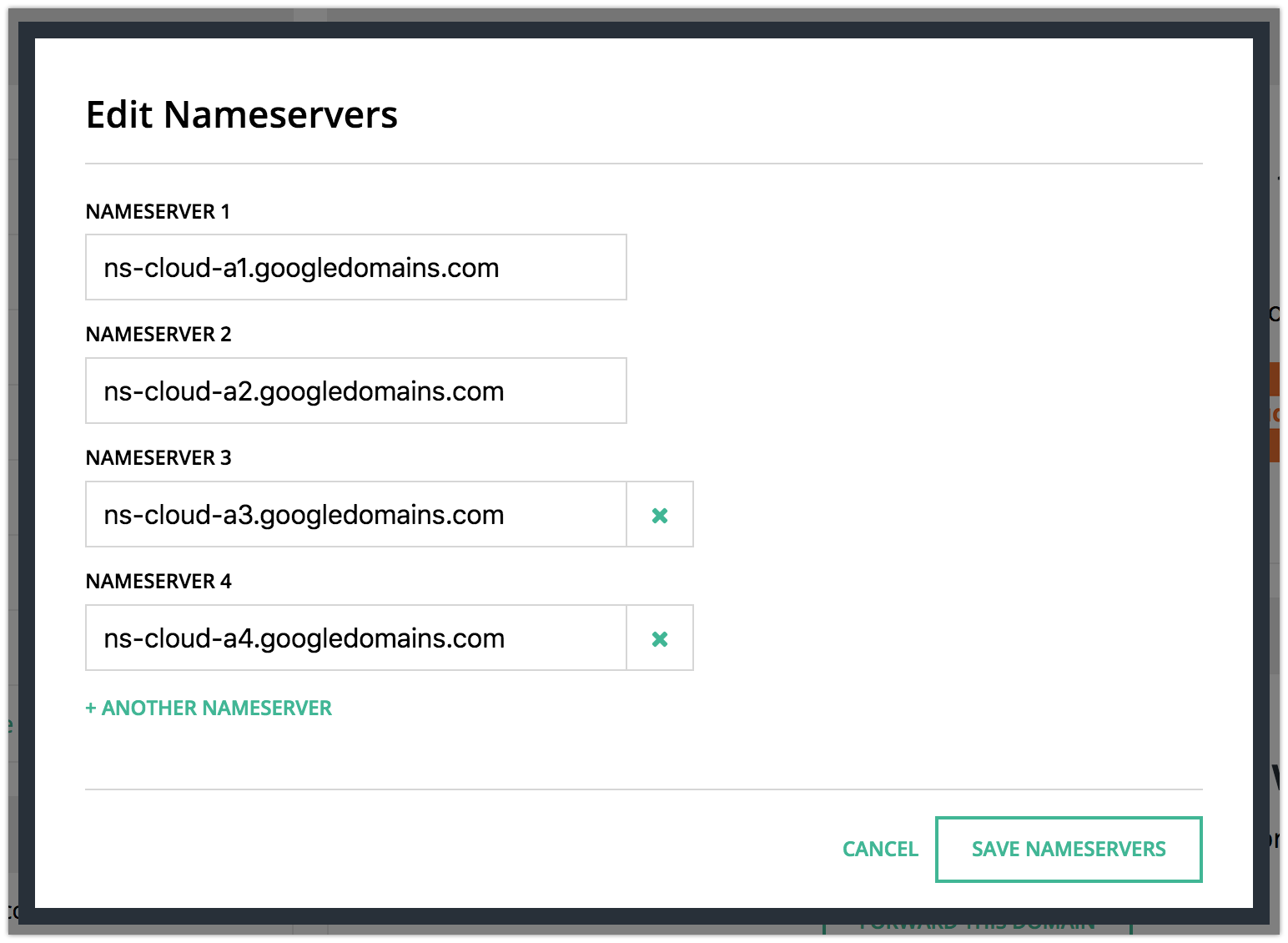
Finally, you’ll update the nameservers to point to your DNS provider. I use a few different registrars, but they all make this part pretty easy. In this particular case, I was using Hover – all I had to do was click their ‘Edit Nameservers’ link near the domain I wanted to adjust, and put in Google’s nameserver addresses:
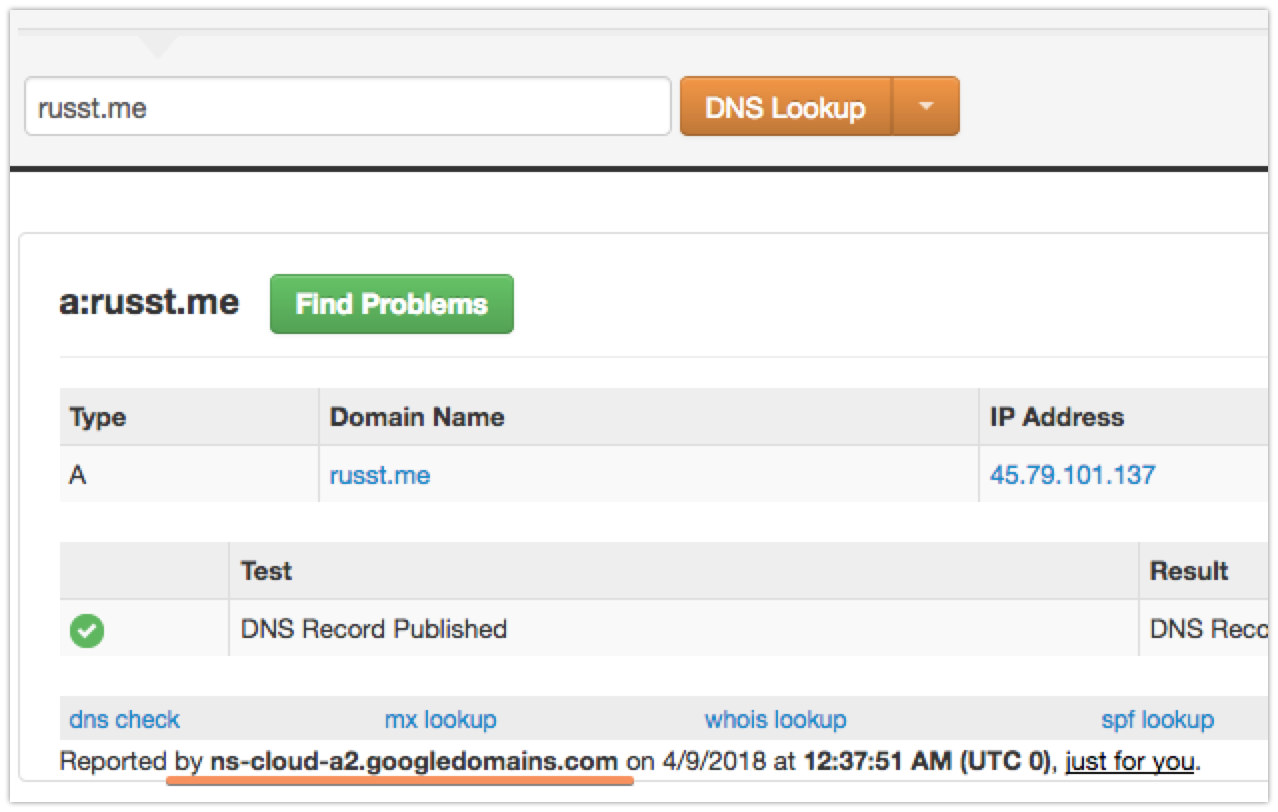
You’ll need to put in whatever your DNS provider wants, but if you’re using Google, the above should work. Once you’ve done that, you might have to wait a few minutes for your DNS to switch over to your new provider. It only took a couple of minutes in my case. I used the DNS lookup tool at MxToolbox to figure out when it switched. It shows your nameserver at the bottom, like this:
Once that’s updated to your new provider, you’re ready to get issuing certificates!
Using Docker to Issue the Certificates
Now, we can do something really nifty here to renew our accounts. Instead of installing certbot-auto on our server, we can just always use the latest up-to-date version in a preconfigured, lightweight Docker container. Sure, this requires you having Docker installed, but who doesn’t these days? If you’d rather, you can do this all manually with your own certbot-auto installation, but I chose to go the Docker route, for simplicity’s sake.
Now it’s actually pretty simple to just run our Docker container. We just need to get the correct arguments, and we’ll be good to go. Note, this does require that you have locations set up where you want to put your certificates, otherwise they’ll just float off into the ether when your container shuts down.
Configuring our Volumes
So first up, let’s create the place we want our certificates to be placed. In my case, I’m going to stick with the default, since my server has already been storing Let’s Encrypt certificates there anyway: /etc/letsencrypt. This is where Let’s Encrypt stores all its configuration and certificates by default. If you’re putting it somewhere else, go ahead and create that directory. Keep note of it for later, naturally. Later, we’re going to map our Docker container to use that as a volume.
Next up, we need to create the place where Let’s Encrypt will store backups. I guess this isn’t strictly necessary (mine is empty anyway), but I figure it can’t hurt. By default it’s in /var/lib/letsencrypt. So we’ll also be mounting that.
Finally, we need to mount the directory where you put your GCP service account’s credentials. I’ve put mine in ~/.secrets/certbot and changed the name to google.json, but you can put it wherever you want and call it whatever you want, really.
So these are going to end up being arguments like this when we run our docker command:
The image that we’re going to be using (assuming you’re sticking with Google DNS) is certbot/dns-google. If you’re using another DNS provider, you can probably figure out pretty easily which image you’ll need.
In the command itself, we’ll also need to use the certonly command, signifying to certbot that we don’t want to have it try to actually install the certificates for us, we only want it to issue them. I personally prefer installing them myself anyway, and that would be very difficult and/or impossible to do from within a Docker container anyway.
We’re also telling certbot to use Google’s DNS with --dns-google, and we’re giving it the path to the credentials file with --dns-google-credentials <file-path>. The last thing we have to do is manually specify the Let’s Encrypt server that we’re using, because right now, wildcard certs are only supported by one server: --server https://acme-v02.api.letsencrypt.org/directory. That should do it for our arguments.
All this means that our full docker command will look like this:
Of course, if you’ve made any adjustments in the way you’re doing this, you’ll need to adjust the command itself. The final line is the important one, -d '*.russt.me, is telling certbot to issue a new wildcard certificate for *.russt.me. You’ll want to make sure you change it, because, well, I’d rather you not issue certificates for my domain. Plus, unless you’ve hacked my Google DNS account, you probably don’t have access.
With any luck, you’ll see some output that looks a lot like this:
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Plugins selected: Authenticator dns-google, Installer None
Obtaining a new certificate
/usr/local/lib/python2.7/site-packages/josepy/jwa.py:107: CryptographyDeprecationWarning: signer and verifier have been deprecated. Please use sign and verify instead.
signer = key.signer(self.padding, self.hash)
Performing the following challenges:
dns-01 challenge for russt.me
Unsafe permissions on credentials configuration file: /secrets/google.json
Waiting 60 seconds for DNS changes to propagate
Waiting for verification...
Cleaning up challenges
IMPORTANT NOTES:
- Congratulations! Your certificate and chain have been saved at:
/etc/letsencrypt/live/russt.me-0001/fullchain.pem
Your key file has been saved at:
/etc/letsencrypt/live/russt.me-0001/privkey.pem
Your cert will expire on <date>. To obtain a new or tweaked
version of this certificate in the future, simply run certbot
again. To non-interactively renew *all* of your certificates, run
"certbot renew"
I’ve cleaned it up a bit, but that’s the gist. I chose to ignore the ‘Unsafe permissions’ warning, since I’m running this in a Docker container anyway and the file on my system actually does have the correct permissions.
Last Thoughts
I’ll leave the configuration and use of these certificates up to you. Hopefully, you have some idea of how to use the certificates on your own server. If not, there are guides all over that should help you out.
I’m extremely thankful to both the EFF and to Let’s Encrypt for enabling us all to issue free SSL certificates, and it’s even better now that they’re letting us issue wildcard certificates. If you’re also feeling thankful, head on over to the EFF’s donation page or Let’s Encrypt’s donation page and drop a donation for them. The web will thank you for it.
If you’ve got any questions or comments, feel free to drop them in the comments below! I’ll do my best to get back to you. Extra props if you correct an error or tell me a better way to do this.
Sometimes, you've just got a big codebase. Maybe you want to put that codebase into a Docker image. Sure, you could mount it, but sometimes that's either not an option or would be too much trouble. In those cases, it's nice to be able to cram your big 'ole codebase into images quickly.
Overview
To accomplish this, we're going to have 3 main layers in our image. Of course, you're welcome to add as many layers as you want, or even take one away. We'll just use 3 for demo purposes – and because that's what's worked in my situation.
The first image will be what we call the 'base' image. It's the one that we're going to copy our code into. On top of that, we'll build an image with our dependencies – it's our 'dependency' image. Finally, we've got our 'incremental' image, which just has our code updates. And that's it. So three images: base, dependency, and incremental.
Luckily, the first two images don't have to build quickly. They're the images that we use to prepare to build the incremental image, so that the incremental build can be quick when we need it.
The Base Image
So the first image, the base image, has our codebase and any universal dependencies. The reason we don't want to put other dependencies in here is because we want to be able to use this 'base' image for any type of task that will require our code. For example, if we have JavaScript tests and, say, PHP tests, they'll probably require different dependencies to run. While we may have a huge codebase, we're still trying to stick to the idea that Docker images should be as small as possible.
This image is actually pretty simple to set up. Here's an example of a Dockerfile:
FROM centos:latest
RUN yum -y install patch && yum -y clean all
COPY repo /var/repo
ARG sha=unknown
LABEL sha=$sha
You'll notice that I'm installing the patch utility. That's because we're going to use this in the incremental image later on to apply a diff to our code. If you have any binary files in your image, you might want to install git instead, because git handles binary diffs, where patch doesn't.
Now, at the end there, we're doing something that you don't necessarily see in every Dockerfile. When we build this image, there are a few more things we should do. We're including the sha argument so that later on we can generate the right diff that we need to apply to get the latest code. We need to pass this in to the docker build command as a --build-arg, and this last bit of the Dockerfile will add that as a label to the image itself. You can see an example on Stack Overflow.
We also should avoid copying in parts of the codebase that we don't need in the image. For example, we probably don't need our .git/ folder in our Docker image. There are a couple of ways that we can accomplish this – we can either do a --bare checkout of our repo, or we can just delete the .git folder before we copy it in. I took the first approach, because it allows me to just update my repo and check things out again.
I used a bash script to handle all this, so that I don't have to remember everything and I don't have to worry about accidentally skipping things. Here's what my base image building script looks like, approximately:
#!/bin/bash
# This allows you to pass in an environment variable, but sets a default.
CODE_DIR=${CODE_DIR:-'/var/tmp/repo.git'}
# If the repo already exists, just update it. Otherwise, clone it.
if [ -d "$CODE_DIR" ]; then
echo "Found an existing git clone... Fetching now to update it..."
GIT_DIR=$CODE_DIR git fetch -q origin master:master
else
echo "No clone found. Cloning the entire repo."
git clone --mirror [email protected]:my/repo.git $CODE_DIR
fi
# This grabs the sha we'll be building
BUILD_VERSION=$(GIT_DIR=$CODE_DIR git rev-parse master)
mkdir -p ./repo
# We clean the old directory to make sure it's a 'clean' checkout
rm -rf ./repo/*
# Check out the code
GIT_DIR=$CODE_DIR GIT_WORK_TREE=./repo git checkout $BUILD_VERSION -f
# Build the image
docker build --rm -t base-image:latest --build-arg sha=$BUILD_VERSION
docker push base-image:latest
So, it's not super simple (if you want to skip the .git/ folder), but I think you get the idea. Next, we'll move on to the dependencies image.
The Dependencies Image
This image is really only necessary if you have more dependencies to install. In my particular case, I needed to install things like php, sqlite, etc. Next up, I installed the composer dependencies for my project. If you're using something other than PHP, you can install the dependencies through whatever package manager you're using – like bundler or npm.
My Dockerfile for this image looks a lot like this (the particular incantations you use will depend on the flavor of linux you're using, of course):
FROM base-image:latest
RUN yum -y install \
php7 \
sqlite \
sqlite-devel \
&& yum -y clean all
WORKDIR /var/repo
RUN composer update
This image doesn't necessarily need to have a bash script to build it, but it all depends on what your dependencies look like. If you need to copy other information in, then you might just want one. In my case, I have one, but it's pretty similar to the previous script, so I won't bother to put it here.
The Incremental Image
Now for the fun part. Our incremental image is what needs to build quickly – and we're set up to do just that. This takes a bit of scripting, but it's not super complicated.
Here's what we're going to do when we build this image:
Update/clone our git repo
Figure out the latest sha for our repo
Generate a diff from our original sha (the one the base image has baked-in) and the new sha
When building the image, copy in and apply the diff to our code
To handle all of this, I highly recommend using a shell script. Here's a sample of the script that I'm using to handle the build (with some repetition from the script above):
#!/bin/bash
BASE_IMAGE_NAME=dependency-image
BASE_IMAGE_TAG=latest
# This allows you to pass in an environment variable, but sets a default.
CODE_DIR=${CODE_DIR:-'/var/tmp/repo.git'}
# If the repo already exists, just update it. Otherwise, clone it.
if [ -d "$CODE_DIR" ]; then
echo "Found an existing git clone... Fetching now to update it..."
GIT_DIR=$CODE_DIR git fetch -q origin master:master
else
echo "No clone found. Cloning the entire repo."
git clone --mirror [email protected]:my/repo.git $CODE_DIR
fi
# Get the latest commit sha from Github, use jq to parse it
echo "Fetching the current commit sha from GitHub..."
BUILD_VERSION=$(curl -s "https://github.com/api/v3/repos/my/repo/commits" | jq '.[0].sha' | tr -d '"')
# Generate a diff from the base image
docker pull $BASE_IMAGE_NAME:$BASE_IMAGE_VERSION
BASE_VERSION=$(docker inspect $BASE_IMAGE_NAME:$BASE_IMAGE_VERSION | jq '.[0].Config.Labels.sha' | tr -d '"')
GIT_DIR=$CODE_DIR git diff $BASE_VERSION..$BUILD_VERSION > patch.diff
# Build the image
docker build --rm -t incremental-image:latest -t incremental-image:$BUILD_VERSION --build-arg sha=$BUILD_VERSION
# And push both tags!
docker push incremental-image:latest
docker push incremental-image:$BUILD_VERSION
There are a few things of note here: I'm using jq on my machine to parse out JSON results. I'm fetching the latest sha directly from GitHub, but I could just as easily use a local git command to get it. I'm also passing in the --build-arg, just like we did for our base image, so that we can use it in the Dockerfile as an environment variable and to set a new label for the image.
On that note, here's a sample Dockerfile:
FROM incremental-image:latest
ARG sha=unknown
ENV sha=$sha
LABEL sha=$sha
COPY patch.diff /var/repo/patch.diff
RUN patch < patch.diff
RUN composer update
CMD ["run-my-tests"]
And that's it! In my experience, this is pretty quick to run – it takes me about a minute, which is a lot faster than the 6+ minute build times I was seeing when I built the entire image every time.
Assumptions
I'm making some definite assumptions here. First, I'm assuming that you have a builder where you have git, jq, and docker installed. I'm also assuming that you can build your base and dependency images about once a day without time restraints. I have them build on a cron at midnight. Throughout the day, as people make commits, I build the incremental image.
Conclusion
This is a fairly straightforward method to build up-to-date images with code baked in quickly. Well, quickly relative to copying in the entire codebase every time.
I don't recommend this method if building your images quickly isn't a priority. In my case, we're trying to build these images and run our tests in under 5 minutes – which meant that a 5 minute image build time obviously wasn't acceptable.
Last week, I found myself needing to filter things alphabetically, using regex. Basically, this is because PHPUnit lets you filter what tests you run with regex, and we (we being Etsy) have enough tests that we have to split them into many parts to get them to run in a reasonable amount of time.
We've already got some logical splits, like separating unit tests from db-related integration tests and all that jazz. But at some point, you just need to split a test suite into, say, 6 pieces. When the option you have to do this is regex, well, then you just have to split it out by name.
Splitting Tests by Name? That's not Smart.
No, no it's not. But until we have a better solution (which I'll talk about in a later post), this is what we're stuck with. Originally, we just split the alphabet into the number of pieces we required and ran the tests that way. Of course, this doesn't result in even remotely similar runtimes on your test suites.
Anyway, since we're splitting things up by runtime but we're stuck with using regex, we might as well use alphabetic sorting. That'll result in relatively short regular expressions compared to just creating a list of tests.
To figure out where in the alphabet to make the splits for our tests, I downloaded all of our test results for a specific test suite and ran it through a parser that could handle JUnit-style output (XML files with the test results). I converted them into CSV's, and then loaded them into a Google Spreadsheet:
Tests in Google Sheets
This made it trivial to figure out where to split the tests alphabetically to even out the runtimes. The problem was, the places where it made sense to split our tests weren't the easiest places to create an alphabetic split. While it would've been nice if the ranges had been, say, A-Cd or Ce-Fa, instead they decided to be things like A-Api_User_Account_Test or Shop_Listings_O-Transaction_User_B.
It's not easy to turn that into regex, but there is at least a pattern to it. I originally tried creating the regex myself – but quickly got in over my head. After about 100 characters in my regex, my brain was fried.
I decided that it'd be easier, quicker, and less error-prone to write a script that could handle it for me.
Identifying the Pattern
It's really quite simple once you break it down. To find if a String is between A and Bob (not including Bob itself), you need a String that meets the following conditions:
Starts with A or a, OR
Starts with B or b, AND:
The second character is A-M or a-m OR
The second character is O or o, AND:
The third character is A or a
In a normal 'ole regular expression, this looks like the following (ignoring all special characters):
^[Aa].*|^([Bb](.|[Oo]([Aa]|$)|$)).*$
Now, if we've got something that complicated just to find something up to Bob, you can likely figure out that the rule would get much longer if you have many characters, like Beta_Uploader_Test_Runner.
There's a recognizable pattern, but once again, it's pretty complex and hard for my weak human brain to grok when it gets long. Luckily, this is what computers are very, very good at.
Formulating the Regex
To get a range between two alphabetic options, you generally need 3 different regex rules. Let's say we're looking for the range Super-Whale. First, you need the range from the starting point to the last alphabetic option that still starts with the same letter. So, essentially, you need Super-Sz. The second thing you need is anything that starts with a letter between the first letter of the starting point and the first letter of the end point. So our middle range would be T-V. The last part needs to be W-Whale.
By way of an example, here's a more simple version of the first part – in this case, it's Hey-Hz, color-coded so that you can see what letter applies to which part of the regular expression:
Next up, we're using the same word as if it were the second part. In this case, H-Hey:
Since the middle part is super simple, I won't bother detailing that. With those three elements, we've got our regex range. Of course, there are some more details around edge cases and whatnot, but we'll ignore those for now. It's much simpler for the purposes of blog posts.
Doing some Test-Driven Development
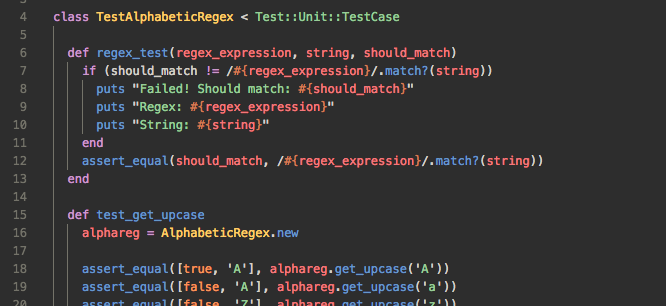
I decided that the best way to make this, you know, actually work, was to write a bunch of tests that would cover many of the edge cases that I could hit. I needed to make sure that these would work, and writing a bunch of tests is a good way to do so.
This helped me know exactly what was going wrong, and I wrote more tests as I kept writing the code. For every method that I wrote, I wrote tests to go along with it. If I realized that I had missed any necessary tests, I added them in, too.
Overall, I'd say this significantly increased my development speed, and it definitely helped me be more confident in my code. Tests are good. Don't let anyone tell you otherwise.
The Code on GitHub
Of course, it doesn't make sense to restrict this code to just me. I couldn't find any good libraries to handle this for me, so I wrote it myself. But really, it only makes sense to make this available to a wider audience.
I've still got some issues to work out, and I need to make a Ruby gem out of it, but in the meantime, feel free to play around with the code: https://github.com/russtaylor/alphabetic-regex
I'm really hoping that someone else will find this code to be useful. If anyone has any questions, comments, or suggestions, feel free to let me know!
Hey everyone – I know that very few people are following this, but I wanted to let you all know that I'm going to be posting with a weekly cadence starting again now.
The posts will be almost entirely tech-related, since that's what I do now. I've got a couple of posts in the pipeline already, I just need to flesh them out and provide good examples.
I may throw in a photography-related post once in awhile, since that's one of my biggest hobbies, and I have a lot of fun with it.
Anyway, I just wanted to get this out there publicly so that I will be forced to be more accountable to it.
I was recently given a sample of Anker’s new 6ft USB-C to USB A cable (They also come in a 3 foot variant). Actually, I guess I should say that I was given two samples, since they come in a pack. I’ve been using them over the past week and a half, and I’ve got to say, I’m very impressed. Granted, I think you could successfully classify me as an Anker fanboy, because I love pretty much every single one of their products that I have.
These cables are no exception. The nylon wrapping is awesome – to me it seems far superior to just a rubber cable. It’s more durable, it’s super flexible, and it really feels like it’s built to last. The connections at the end are sturdy and they hold well when plugged in to both my phone and my charger/computer. Finally, the red color on the nylon wrap looks pretty cool. It looks a lot nicer than either a plain black or plain white cable, and I think it’ll look a lot better when dirty than rubber white cables do.
I think my only complaint about the nylon wrap would be that I think it’d tend to fray a bit over time. Since I haven’t had these cables for very long, I can’t say whether or not that’ll actually happen, just that it seems likely. Of course, even if it does happen, it’d be easy enough to clean them up with a quick pass of a lighter.
Overall, these are another great product in Anker’s lineup. I’m looking forward to using them for at least the next few years.
Recently, I hit an issue where building docker images on containers meant that the Docker cache wasn’t being persisted from one build to the next. So even if you ran an identical build on the next run, it’d still rebuild every step, costing you valuable time.
Luckily, it’s not too difficult to save your Docker cache and to restore it (or distribute it) to other machines. It’s a bit more difficult than it used to be, but with a bit of scripting magic, it’s easy enough.
How it Used to Be
Apparently (though before I started working much with Docker), when you used to push a Docker image to a remote repository, it’d include all layers of that image. That means when you pulled in image, you’d get its entire history as well. This made things easier for distributing or restoring the cache, because all you had to do was pull the image. Unfortunately, it also made things clunky, in that you had to download more data than you actually needed to run the image.
Shortly after that, Docker supported saving the entire cache using docker save -o file.tar <image_name> and restoring it using docker load -i file.tar. But now, docker save has been streamlined, too, so saving your cache isn’t quite as simple as it used to be.
Saving Your Cache
Luckily, despite those changes, you can still use the docker save command to get your image’s full cache – the catch is that you have to save all the layers listed in your image’s docker history.
So, to save your image’s cache, run the following command: docker save -o output.tar $(docker history -q <image_name>[:image_tag] | tr '\n' ' ' | tr -d '<missing>')
This runs docker history with the -q (quiet) tag, so it only shows the ids of each layer. Since you’re probably building FROM another image, much of the history will show <missing>, because you don’t have the entire history of the image you’re building FROM.
Next up, the command pipes the output to tr twice, to clear out any \ns and any <missing> output. So, in the end, you get a list of image IDs passed directly to docker save.
Loading Your Cache
Loading your cache is exactly how it used to be – after you’ve copied or moved the tar file containing your cache, just run docker load -i <filename> and you’ll have your cache all ready to go!